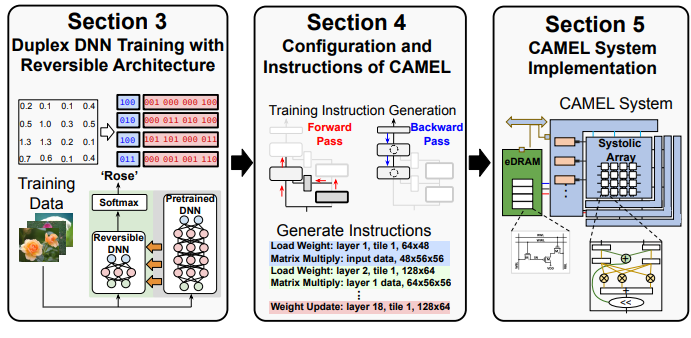
CAMEL: Co-designing AI Models and eDRAMs for Efficient On-device Learning
We adopt the principles of algorithm and hardware co-design, introducing a family of reversible DNN architectures that effectively decrease data lifetime and storage costs throughout training. Additionally, we present a highly efficient on-device training engine named CAMEL, which leverages eDRAM as the primary on-chip memory (Paper).
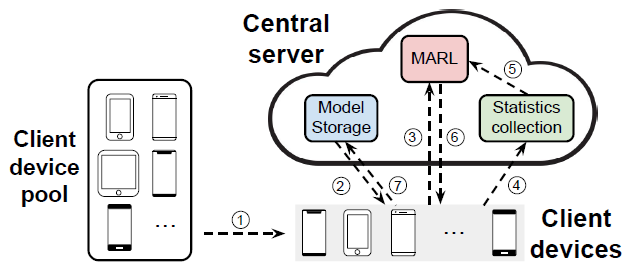
A Multi-agent Reinforcement Learning Approach for Efficient Client Selection in Federated Learning
We design an efficient Federated learning (FL) framework which jointly optimizes model accuracy, processing latency and communication efficiency, all of which are primary design considerations for real implementation of FL. Inspired by the recent success of Multi Agent Reinforcement Learning (MARL) in solving complex control problems, we present FedMarl, a federated learning framework that relies on trained MARL agents to perform efficient client selection (Paper).
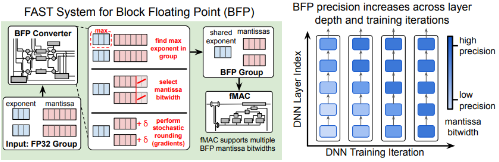
FAST: DNN Training Under Variable Precision Block Floating Point with Stochastic Rounding
We propose a Fast First, Accurate Second Training (FAST) system for DNNs, where the weights, activations, and gradients are represented in BFP. FAST supports matrix multiplication with variable precision BFP input operands, enabling incremental increases in DNN precision throughout training (Paper).
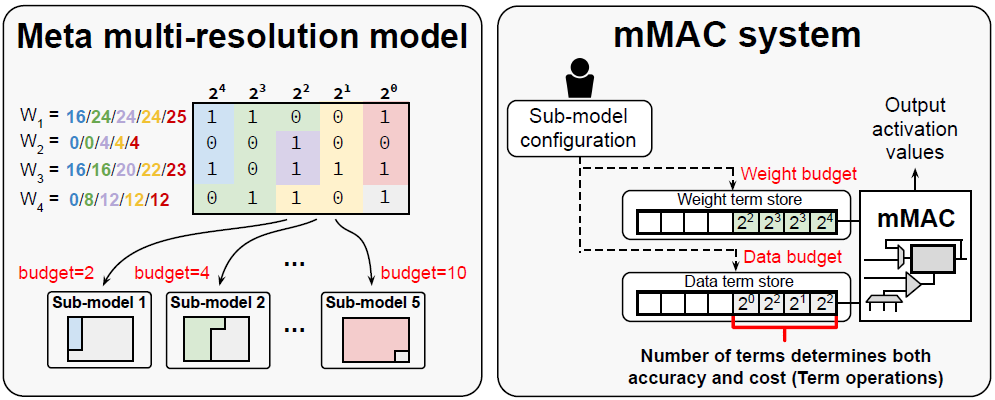
Training for Multi-resolution Inference Using Reusable Quantization Terms
We describe a novel training approach to support inference at multiple resolutions by reusing a single set of quantization terms (the same set of nonzero bits in values). The proposed approach streamlines the training and supports dynamic selection of resolution levels during inference (Paper).
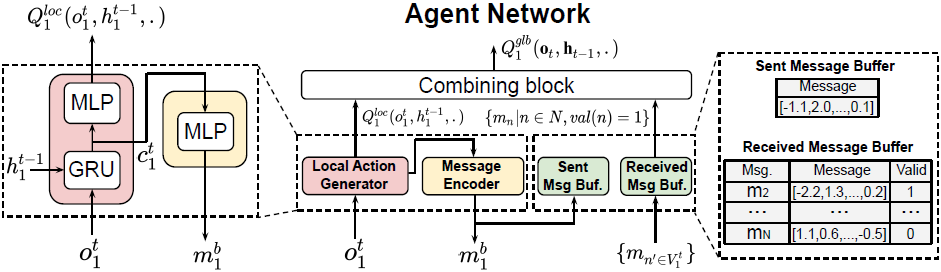
Succinct and Robust Multi-Agent Communication With Temporal Message Control
We present Temporal Message Control (TMC), a simple yet effective approach for achieving succinct and robust communication in MARL. TMC applies a temporal smoothing technique to drastically reduce the amount of information exchanged between agents. Experiments show that TMC can significantly reduce inter-agent communication overhead without impacting accuracy. Furthermore, TMC demonstrates much better robustness against transmission loss than existing approaches in lossy networking environments (Paper).
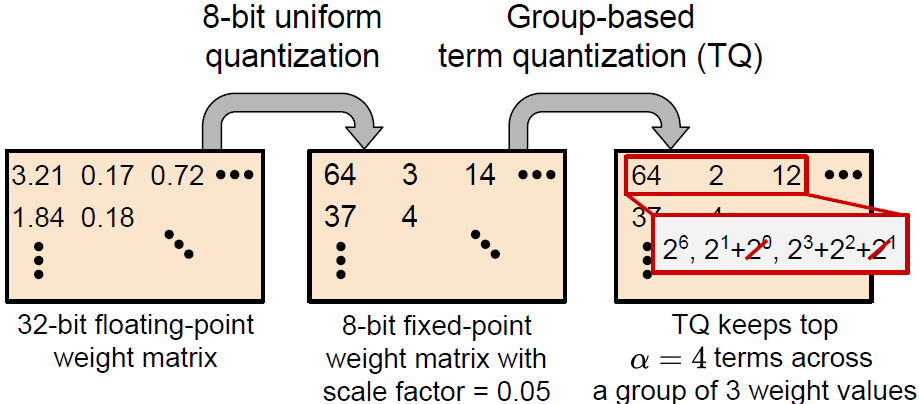
Term Quantization: Furthering Quantization at Run Time
We present a novel technique, called Term Quantization (TQ), for furthering quantization at run time for improved computational efficiency of deep neural networks already quantized with conventional quantization methods. TQ operates on power-of-two terms in expressions of values. In computing a dot-product computation, TQ dynamically selects a fixed number of largest terms to use from values of the two vectors (Paper).
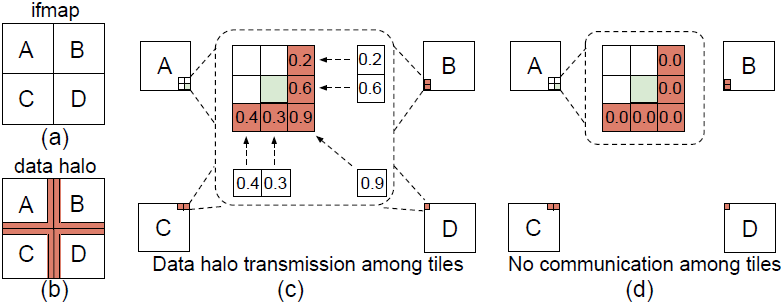
Adaptive Distributed Convolutional Neural Network Inference at the Network Edge with ADCNN
We present a novel approach for running CNN inference tasks in Edge computing environments. Specifically, we study the distributed CNN inferencing problem in dynamic edge computing environments. We present ADCNN, an efficient partitioning framework for fast CNN inference over edge cluster (Paper).
Efficient Communication in Multi-Agent Reinforcement Learning via Variance Based Control
We propose Variance Based Control (VBC), a simple yet efficient technique to improve communication efficiency in MARL. By limiting the variance of the exchanged messages between agents during the training phase, the noisy component in the messages can be eliminated effectively, while the useful part can be preserved and utilized by the agents for better performance (Paper).

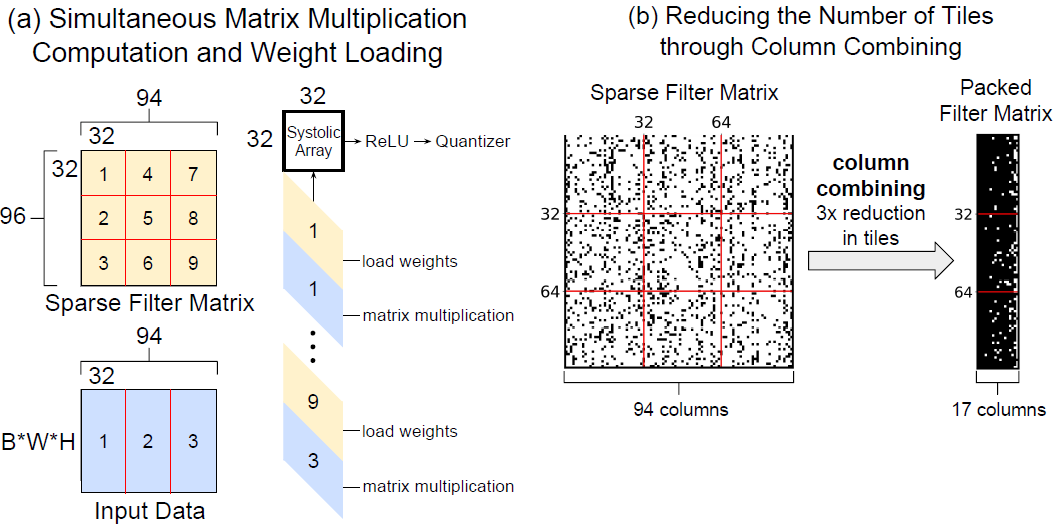
Packing Sparse Convolutional Neural Networks for Efficient Systolic Array Implementations: Column Combining Under Joint Optimization
We introduce a novel approach of packing sparse convolutional neural networks into a denser format for efficient implementations using systolic arrays. By combining multiple sparse columns of a convolutional filter matrix into a single dense column stored in the systolic array, the utilization efficiency of the systolic array can be substantially increased (e.g., 8x) due to the increased density of nonzero weights in the resulting packed filter matrix (Paper).
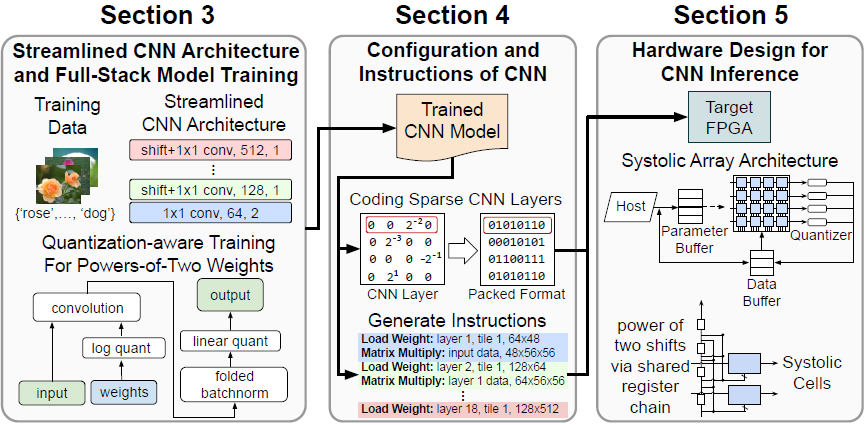
Full-stack Optimization for Accelerating CNNs with FPGA Validation
We present a full-stack optimization framework for accelerating inference
of CNNs and validate the approach with a field-programmable gate array (FPGA) implementation. By jointly optimizing CNN models, computing architectures, and hardware implementations, our full-stack approach achieves unprecedented performance in the trade-off space characterized by inference latency, energy efficiency, hardware utilization, and inference accuracy (Paper).